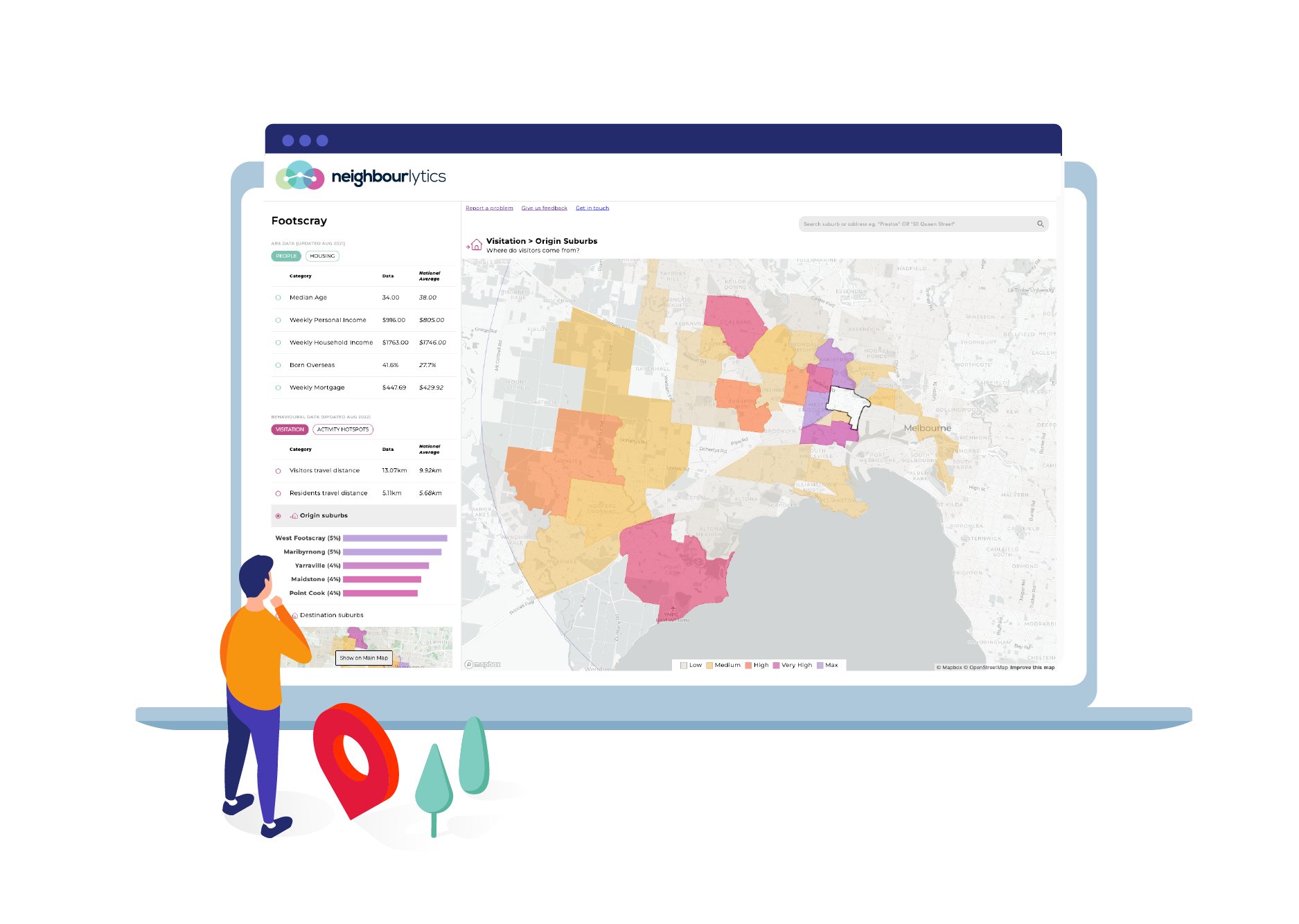
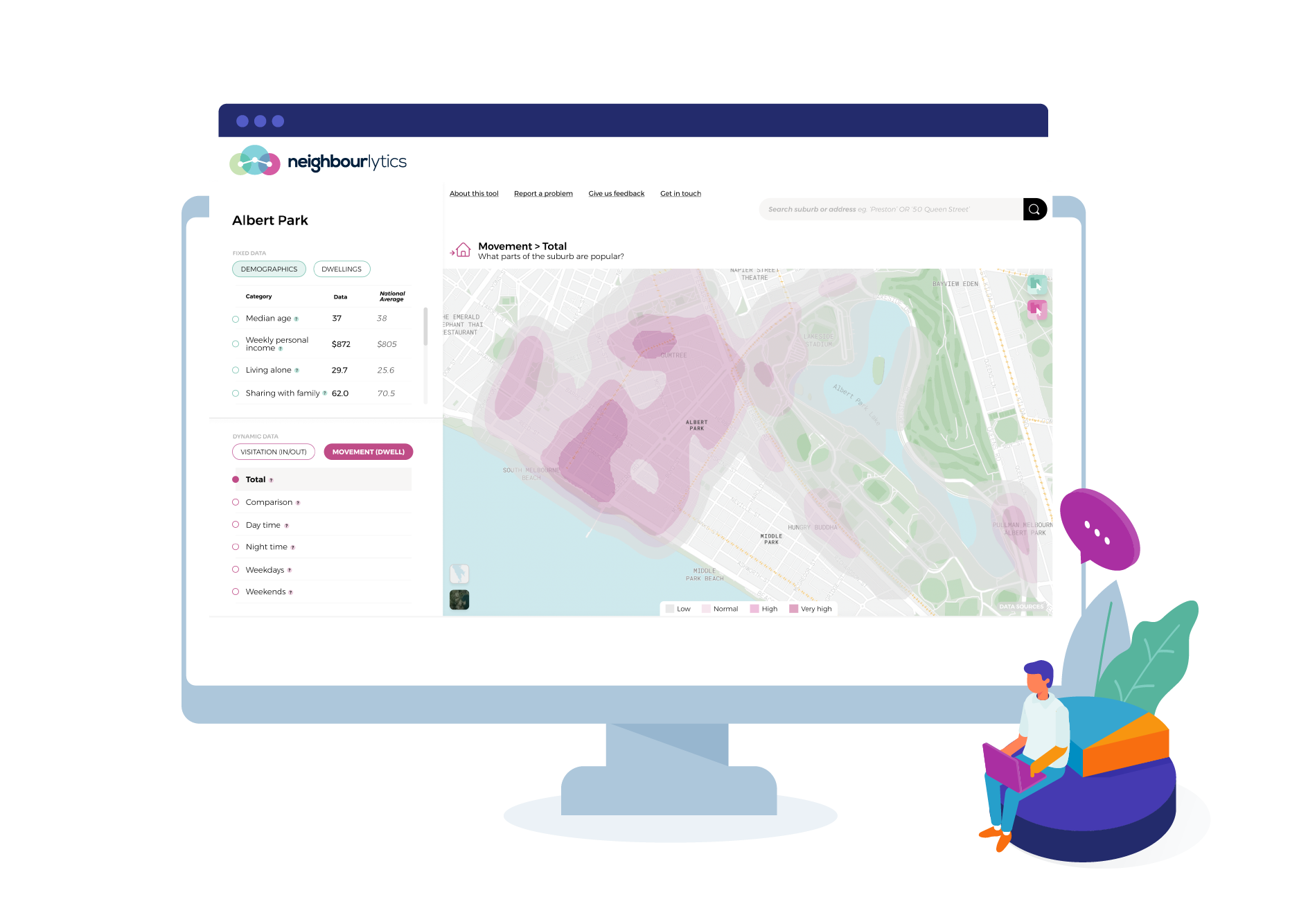
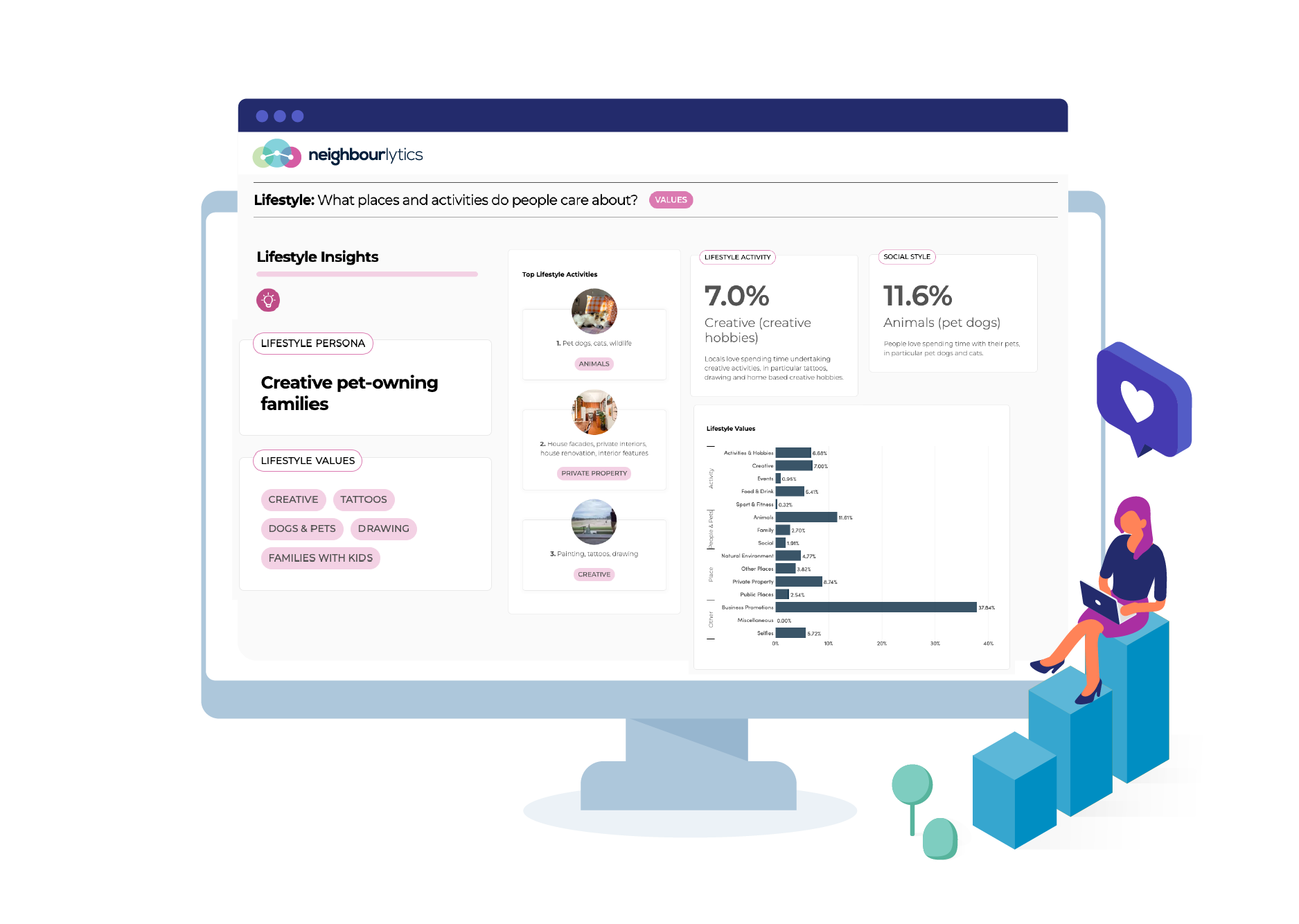
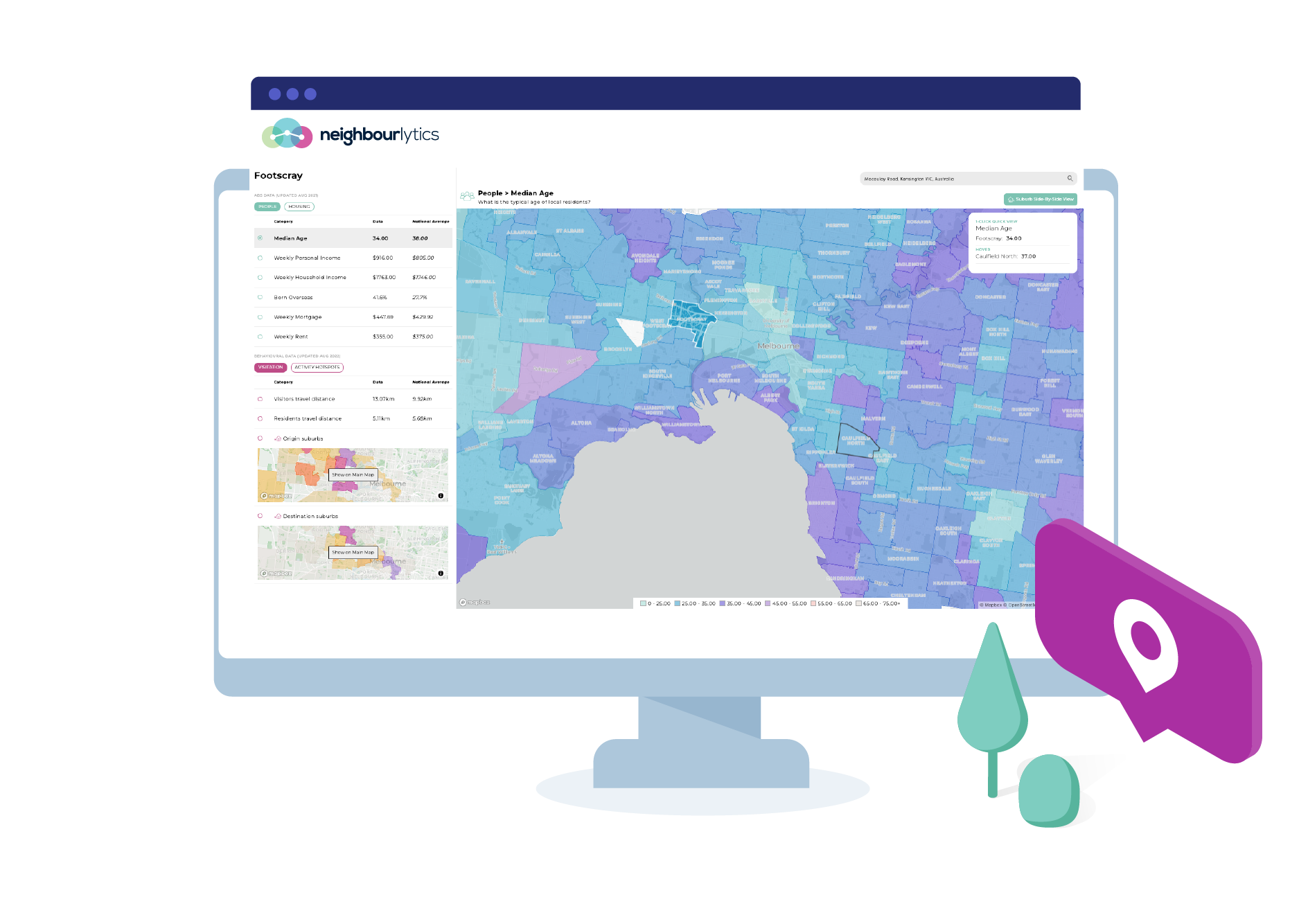
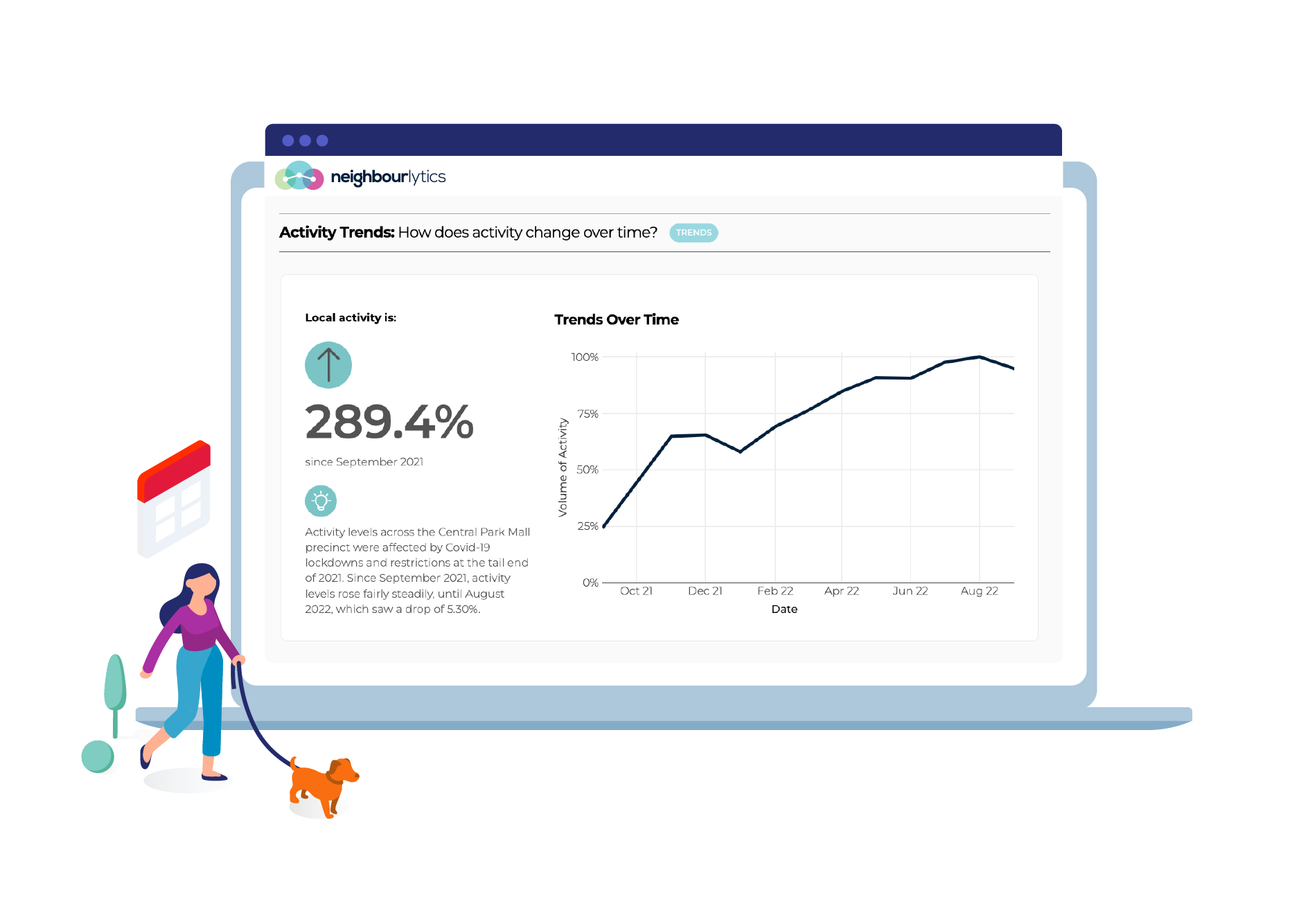
Discover trade areas and uncover new destinations based on where people live, work and move around. Use this to identify the actual trade area or target market locations based on real-life behaviours.
Use the latest lifestyle values to better understand your target customer and optimise place visioning, marketing strategies and development proposals.
Drill down into which places are most important, and which are missing so you can target your investment in retail, hospitality, public space, health and wellness and more.
Neighbourlytics helped us see the community in a quantifiable way, with new information about popular amenities and gaps. This gave us new visibility into the local context, and helped us understand a ‘place’ in a more granular way, before diving into solutions. This in turn has driven a richer level of innovation within our design teams approach.
Heath Gledhill
Integrated Design and Precincts Capability Leader, Aurecon
In a lifetime of social sciences I have never seen anything as good as the system you guys have put together… it’s a stunning piece of work. Grounded in solid theory, nimble in its analysis, insightful in its results and a very practical tool for us within Local government to respond and change things.